informasi anak utm
15:04
3
Analytical Hierarchy Process (AHP) adalah suatu metode pengambilan keputusan dengan melakukan perbandingan berpasangan antara kriteria pilihan dan juga perbandingan berpasangan antara pilihan yang ada. Permasalahan pengambilan keputusan dengan AHP umunya dikomposisikan menjadi kriteria, dan alternative pilihan.
Contoh permasalahan:
Bagian terpenting dari proses analisis adalah 3 (tiga) tahapan berikut:
1. Nyatakan tujuan analisis: Memilih mobil baru
2. Tentukan kriteria: style, kehandalan, dan konsumi bahan bakar
3. Tentukan alternative pilihan: Avansa, Xenia, Ertiga, Grand Livina
Informasi ini kemudian disusun membentuk pohon bertingkat
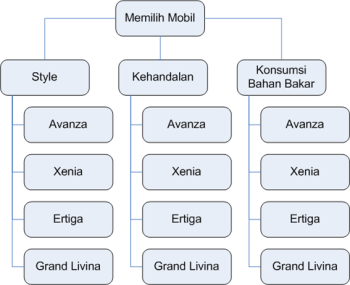
Bagian terpenting dari proses analisis adalah 3 (tiga) tahapan berikut:
1. Nyatakan tujuan analisis: Memilih mobil baru
2. Tentukan kriteria: style, kehandalan, dan konsumi bahan bakar
3. Tentukan alternative pilihan: Avansa, Xenia, Ertiga, Grand Livina
Informasi ini kemudian disusun membentuk pohon bertingkat
Informasi yang ada kemudian di-sintesis untuk menentukan peringkat relative dari alternative pilihan yang ada. Kriteria dari jenis qualitative dan quantitative dapat diperbandingkan menggunakan informed judgement untuk menghitung bobot dan prioritas.
Bagaimana menentukan tingkat kepentingan relative dari kriteria yang ada?
Hal ini dapat dilakukan dengan judgement untuk menentukan peringkat dari kriteria. Dalam sebuah sistem berbasis AHP, judgement ini diberikan oleh user pengguna sistem dan dilakukan pada saat user bermaksud melakukan proses AHP dan melihat rekomendasi.
Misalnya:
1. Kehandalan 2 kali lebih penting dari style
2. Style 3 kali lebih penting dari konsumsi bahan bakar
3. Kehandalan 4 kali lebih penting dari konsumsi bahan bakar
1. Kehandalan 2 kali lebih penting dari style
2. Style 3 kali lebih penting dari konsumsi bahan bakar
3. Kehandalan 4 kali lebih penting dari konsumsi bahan bakar
Selanjutnya dengan pairwise comparison (perbandingan berpasangan), tingkat kepentingan satu kriteria dibandingkan dengan yang lain dapat diekspresikan.
Nilai yang digunakan:
1: equal
2: moderate
3: strong
4: very strong
5: extreme
1: equal
2: moderate
3: strong
4: very strong
5: extreme
Dari judgement di atas bisa dibuatkan tabel perbandingan berpasangan sebagai berikut:

Bagaimana mengubah matrik berpasangan ini menjadi peringkat dari kriteria? Jawabannya: Eigenvector
Berikut cara untuk mencari solusi eigenvector:
1. Cara komputasi yang singkat yang bisa digunakan untuk mendapatkan peringkat adalah dengan menggunakan matrik berpasangan ini sebagai sebagai dasar penghitungan kuadrat matrik berpasangan setiap saat.
2. Jumlah setiap baris dihitung dan dinormalisasi
3. Perhitungan dihentikan apabila perbedaan dari jumlah-jumlah ini dalam dua penghitungan yang berturutan lebih kecil dari suatu angka.
1. Cara komputasi yang singkat yang bisa digunakan untuk mendapatkan peringkat adalah dengan menggunakan matrik berpasangan ini sebagai sebagai dasar penghitungan kuadrat matrik berpasangan setiap saat.
2. Jumlah setiap baris dihitung dan dinormalisasi
3. Perhitungan dihentikan apabila perbedaan dari jumlah-jumlah ini dalam dua penghitungan yang berturutan lebih kecil dari suatu angka.
Tahan 1: Kuadratkan Matrik Berbasangan

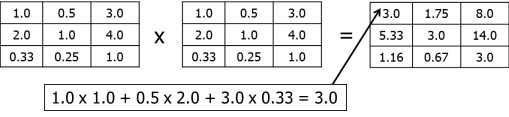
Tahap 2: Hitung Eigenvector pertama
1. Jumlahkan baris
2. Jumlahkan jumlah dari baris-baris yang ada
3. Normalisasi nilai jumlah dari masing-masing baris
2. Jumlahkan jumlah dari baris-baris yang ada
3. Normalisasi nilai jumlah dari masing-masing baris


Angka normalisasi pertama yang sebesar 0.3194 didapatkan dengan membagi angka 12.75/39.9165
Jadi eigenvector yang pertama adalah:

Proses ini terus diulang: kuadrat, jumlahkan, dan normalisasikan
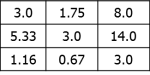
Dikuadratkan, dijumlah, dan dinormalisasi menjadi:



Jadi eigenvector yang kedua adalah:
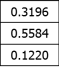
Perbedaannya memang sudah kecil, apalagi kalau dihitung satu putaran lagi:

Apa arti nilai eigenvector ini? Melihat pada nilai dari eigenvector bisa dikatakan bahwa:
kriteria yang pertama adalah peringkat nomor 2 terpenting,
kriteria yang kedua adalah peringkat 1 terpenting, dan
kriteria yang ketiga adalah peringkat nomor 3 terpenting
kriteria yang pertama adalah peringkat nomor 2 terpenting,
kriteria yang kedua adalah peringkat 1 terpenting, dan
kriteria yang ketiga adalah peringkat nomor 3 terpenting
Berikut adalah pohon dengan bobot pada kriterianya:

Selanjutnya, bagaimana menentukan peringkat alternative pilihan?
Untuk alternative pilihan, juga dilakukan perbandingan berpasangan terhadap kriteria masing-masing. Judgement dalam proses ini umumnya dilakukan berbasis pada data/informasi tentang alternative pilihan (quantitative approach) atau kalau tidak tersedia data/informasi tersebut, dapat dilakukan dengan judgement dari pakar terkait pemilihan alternative tersebut (qualitative approach).
Di dalam sebuah sistem, proses untuk menentukan nilai kriteria dari masing-masing alternative pilihan dan perhitungan peringkat dilakukan pada saat melakukan entry dan edit data variabel dan kriteria alternative pilihan.
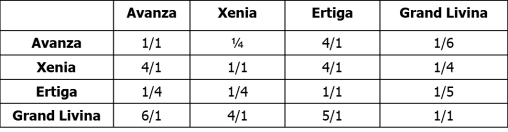
Dalam kasus ini, yang memberikan judgement untuk kriteria style dan kehandalan adalah pakar tentang mobil dengan informasi bersifat qualitative.
Style
Kehandalan
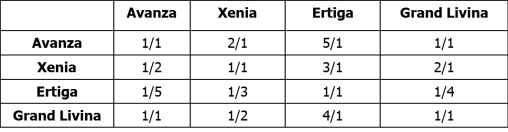
Dari matrik ini dihitung eigenvector, untuk menentukan peringkat dari alternative pilihan untuk masing-masing kriteria.
Peringkat Style

Peringkat Kehandalan

Untuk kriteria konsumsi bahan bakar, ditentukan dengan informasi yang bersifat quantitative sebagai berikut:
Konsumsi Bahan Bakar
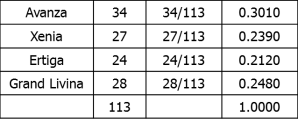
Konsumsi Bahan Bakar
Dengan menormalisasi informasi bersifat quantitative, akan bisa didapatkan peringkat konsumsi bahan bakar untuk masing-masing alternative pilihan.
Dengan demikian bobot kriteria dan alternative pilihan sudah terlengkapi, sehingga pohon keputusan tergambar menjadi:
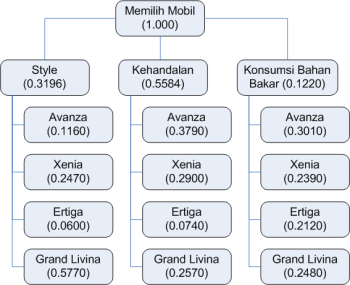
Untuk mendapatkan hasil keputusan, masing-masing bobot untuk alternative pilihan dikalikan dengan bobot dari kriteria dalam bentuk perkalian matrik sebagai berikut:
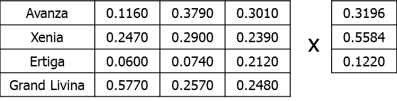
Sehingga perhitungan untuk mobil Avanza keseluruhan nilai masing-masing alternative pilihan adalah sebagai berikut:

Sehingga pilihan yang paling bagus untuk kasus pengambilan keputusan ini adalah mobil dengan tipe Grand Livina.







